
파이썬 데이터 분석 예제 _ 서울시 각 자치구 cctv와 인구 데이터 분석
파이썬
1. 개요
국감브리핑을 통해 강남3구의 주민들이 거주지 체감 안전도를 높게 생각한다는 기사 확인
http://news1.kr/articles/?1911504
분석 내용
1. 서울시 각 자치구 별 CCTV 수 파악
2. 인구 대비 CCTV 비율을 파악해 순위 비교
3. 인구 대비 CCTV의 평균치를 확인 후 CCTV가 가장 부족한 자치구 확인
4. 단순한 그래프 표현에서 한 단계 더 나아가 경향을 확인하고 시각화
2. 모듈 import
conda install -c anaconda xlrd모듈 import 전, 아나콘다프롬프트 혹은 spyder 콘솔에 상기 코드를 입력해 모듈이 원활하게 수행되도록 함.
#csv, excel 파일 읽기 모듈
import pandas as pd
#숫자 관련 모듈
import numpy as np
#시각화 작업 모듈
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
#사용 컴퓨터의 운영체제 확인 모듈
import platform
#한글 폰트 손상 방지
plt.rcParams['axes.unicode_minus'] = False
#운영체제에 맞는 기본 폰트 설정
if platform.system() == 'Darwin': #애플
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = 'c:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('sorry!')3. 데이터 읽기
3-1. 서울시 cctv 데이터 읽기 및 정제
1) 파일 읽기 : pandas.read_csv('파일경로')
CCTV_seoul = pd.read_csv('./cctv/data1/01. CCTV_in_Seoul.csv', encoding='utf-8')
2) 열 이름 확인 : DataFrame.columns / DataFrame.columns[index열]
CCTV_seoul.columns
CCTV_seoul.columns[0]
CCTV_seoul.head()
3) index 열 이름 변경 : DataFrame.rename(columns={DataFrame.columns[index열] : '변경할 이름'}, inplace=True)
CCTV_seoul.rename(columns={CCTV_seoul.columns[0] : '자치구'}, inplace=True)
#변경 여부 확인
CCTV_seoul.columns[0]'기관명'이라고 되어 있는 index 열을 '자치구'로 변경,
inplace를 True로 적용해야 변경사항을 원본 DataFrame에 적용.
3-2. 서울시 인구 데이터 읽기 및 정제
1) 파일 읽기 : pandas.read_excel('파일경로')
#전체 읽어 올 경우
pop_Seoul = pd.read_excel('./cctv/data1/01. population_in_Seoul.xls')
#분석에 유의미한 부분만 선택해 읽어 올 경우
#header=엑셀 행(인덱스) 번호 : 엑셀의 첫 몇 줄로 불필요하면 입력한 숫자만큼 건너뜀
#usecols='엑셀 열 이름, 이름....' / B:구이름, D:인구수, G:한국인, J:외국인, N:고령자(65세이상)
pop_Seoul = pd.read_excel('./cctv/data1/01. population_in_Seoul.xls',
header=2,
usecols='B, D, G, J, N')
pop_Seoul.head()
#결과
'''
자치구 계 계.1 계.2 65세이상고령자
0 합계 10197604.0 9926968.0 270636.0 1321458.0
1 종로구 162820.0 153589.0 9231.0 25425.0
2 중구 133240.0 124312.0 8928.0 20764.0
3 용산구 244203.0 229456.0 14747.0 36231.0
4 성동구 311244.0 303380.0 7864.0 39997.0
'''
2) 각 열 이름 변경
#자치구 : 구별, 계 : 인구수, 계1 : 한국인, 계2 : 외국인, 65세이상고령자 : 고령자
pop_Seoul.rename(columns={pop_Seoul.columns[0] : '자치구',
pop_Seoul.columns[1] : '인구수',
pop_Seoul.columns[2] : '한국인',
pop_Seoul.columns[3] : '외국인',
pop_Seoul.columns[4] : '고령자'}, inplace=True)
pop_Seoul.columns
#결과
'''
Index(['자치구', '인구수', '한국인', '외국인', '고령자'], dtype='object')
'''4. 데이터 전처리
4-1. 서울시 cctv 데이터 파악
13년도 이전과 이후 CCTV 증가율을 나타내는 '최근증가율' 열 추가.
CCTV_seoul.head(5)
CCTV_seoul.tail(5)
#DataFrame에 열 추가 : DataFrame['새 열 이름'] = 추가 예정 데이터
#증가율 = (2014년 + 2015년 + 2016년) / 2013년 이전 * 100
CCTV_seoul['최근증가율'] = (CCTV_seoul['2014년']+CCTV_seoul['2015년']+CCTV_seoul['2016년'])/
CCTV_seoul['2013년도 이전'] * 100
#결과
'''
0 150.619195
1 166.490765
2 125.203252
3 134.793814
4 149.290780
5 53.228621
6 64.973730
7 100.000000
8 188.929889
9 246.638655
10 74.766355
11 139.338235
12 212.101911
13 48.578199
14 63.371266
15 81.780822
16 63.627354
17 104.347826
18 34.671731
19 157.979798
20 53.216374
21 85.237258
22 248.922414
23 147.699758
24 79.960707
Name: 최근증가율, dtype: float64
'''
CCTV_seoul.sort_values(by='최근증가율', ascending=False).head()
#결과
'''
자치구 소계 2013년도 이전 2014년 2015년 2016년 최근증가율
22 종로구 1002 464 314 211 630 248.922414
9 도봉구 485 238 159 42 386 246.638655
12 마포구 574 314 118 169 379 212.101911
8 노원구 1265 542 57 451 516 188.929889
1 강동구 773 379 99 155 377 166.490765
'''4-2. 서울시 인구 데이터 파악
1) 결측치 확인 및 처리
#결측치 NaN 확인 : isnull()
#유일 값 확인 : unique()
#행 삭제 : drop([행index번호])
#'합계' 행 삭제 : 전체 자치구 값의 합계이므로 불필요
pop_Seoul.drop([0], inplace=True)
#'자치구' 열의 유일 값 확인
pop_Seoul['구별'].unique()
#결과
'''
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구', nan],
dtype=object)
'''
#'자치구' 열의 결측치 확인
pop_Seoul[pop_Seoul['구별'].isnull()]
#결과
'''
자치구 인구수 한국인 외국인 고령자
26 NaN NaN NaN NaN NaN
'''
#결측치 행 삭제 _ 해당 행에서의 결측은 데이터에 크게 영향을 미치지 않음
pop_Seoul.drop([26], inplace=True)
pop_Seoul.tail()
#결과
'''
자치구 인구수 한국인 외국인 고령자
21 관악구 525515.0 507203.0 18312.0 68082.0
22 서초구 450310.0 445994.0 4316.0 51733.0
23 강남구 570500.0 565550.0 4950.0 63167.0
24 송파구 667483.0 660584.0 6899.0 72506.0
25 강동구 453233.0 449019.0 4214.0 54622.0
'''
2) 외국인과 고령자 비율 열 생성
외국인과 고령자의 비율을 별도의 열을 생성하여 파악.
#'외국인비율' = '외국인' / '인구수' * 100
pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
#'고령자비율' = '고령자' / '인구수' * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100
#인구수/외국인/외국인비율/고령자/고령자비율을 기준으로 각각 정렬 후 데이터 확인
pop_Seoul.sort_values(by='인구수', ascending=False).head(5)
pop_Seoul.sort_values(by='외국인', ascending=False).head(5)
pop_Seoul.sort_values(by='외국인비율', ascending=False).head(5)
pop_Seoul.sort_values(by='고령자', ascending=False).head(5)
pop_Seoul.sort_values(by='고령자비율', ascending=False).head(5)
#결과
'''
자치구 인구수 한국인 외국인 고령자 외국인비율 고령자비율
9 강북구 330192.0 326686.0 3506.0 54813.0 1.061806 16.600342
1 종로구 162820.0 153589.0 9231.0 25425.0 5.669451 15.615404
2 중구 133240.0 124312.0 8928.0 20764.0 6.700690 15.583909
3 용산구 244203.0 229456.0 14747.0 36231.0 6.038828 14.836427
13 서대문구 327163.0 314982.0 12181.0 48161.0 3.723221 14.720797
'''4-3. CCTV와 인구 데이터 병합 및 정제
1) CCTV와 인구 데이터 병합
새DataFrame = Pandas.merge(DataFrame1, DataFrame2, on='공통 열')
#Pandas.merge(CCTV_seoul, pop_Seoul, on='공통 열')
#만약 두 프레임의 공통 열이 없다면 : left_on='열', right_on='열'
data_result = pd.merge(CCTV_seoul, pop_Seoul, on='구별')
data_result.head()
data_result.tail()
2) 불필요한 열 삭제 : del DataFrame['열']
#2013년도 이전 / 2014년 / 2015년 / 2016년 : 현재에 해당하는 '소계'만 남기고 삭제
#자치구 / 소계 / 최근증가율 / 인구수 / 한국인 / 외국인 / 고령자 / 외국인비율
del data_result['2013년도 이전']
del data_result['2014년']
del data_result['2015년']
del data_result['2016년']
data_result.head()
#결과
'''
자치구 소계 최근증가율 인구수 ... 외국인 고령자 외국인비율 고령자비율
0 강남구 2780 150.619195 570500.0 ... 4950.0 63167.0 0.867660 11.072217
1 강동구 773 166.490765 453233.0 ... 4214.0 54622.0 0.929765 12.051638
2 강북구 748 125.203252 330192.0 ... 3506.0 54813.0 1.061806 16.600342
3 강서구 884 134.793814 603772.0 ... 6524.0 72548.0 1.080540 12.015794
4 관악구 1496 149.290780 525515.0 ... 18312.0 68082.0 3.484582 12.955291
[5 rows x 9 columns]
'''
3) 분석 및 시각화를 위해 '자치구' 열을 index로 설정
DataFrame.set_index('index로 사용될 열', inplace=True)
data_result.set_index('자치구', inplace=True)5. 분석 및 시각화
5-1. 각 데이터 간 연관성 파악을 위해 상관계수 산출 : Numpy.corrcoef()
#고령자비율과 소계 간 상관 관계
np.corrcoef(data_result['고령자비율'], data_result['소계'])
#결과
'''
array([[ 1. , -0.28078554],
[-0.28078554, 1. ]])
'''
#인구수와 소계 간 상관 관계
np.corrcoef(data_result['인구수'], data_result['소계'])
#결과
'''
array([[1. , 0.30634228],
[0.30634228, 1. ]])
'''5-2. 시각화
1) 자치구 및 소계 데이터 시각화
plt.figure()
data_result['소계'].plot(kind='barh',
grid=True,
figsize=(10, 10))
plt.show()
2) 소계를 기준으로 정렬 후 시각화
data_result['소계'].sort_values().plot(kind='barh',
grid=True,
figsize=(10, 10))
plt.show()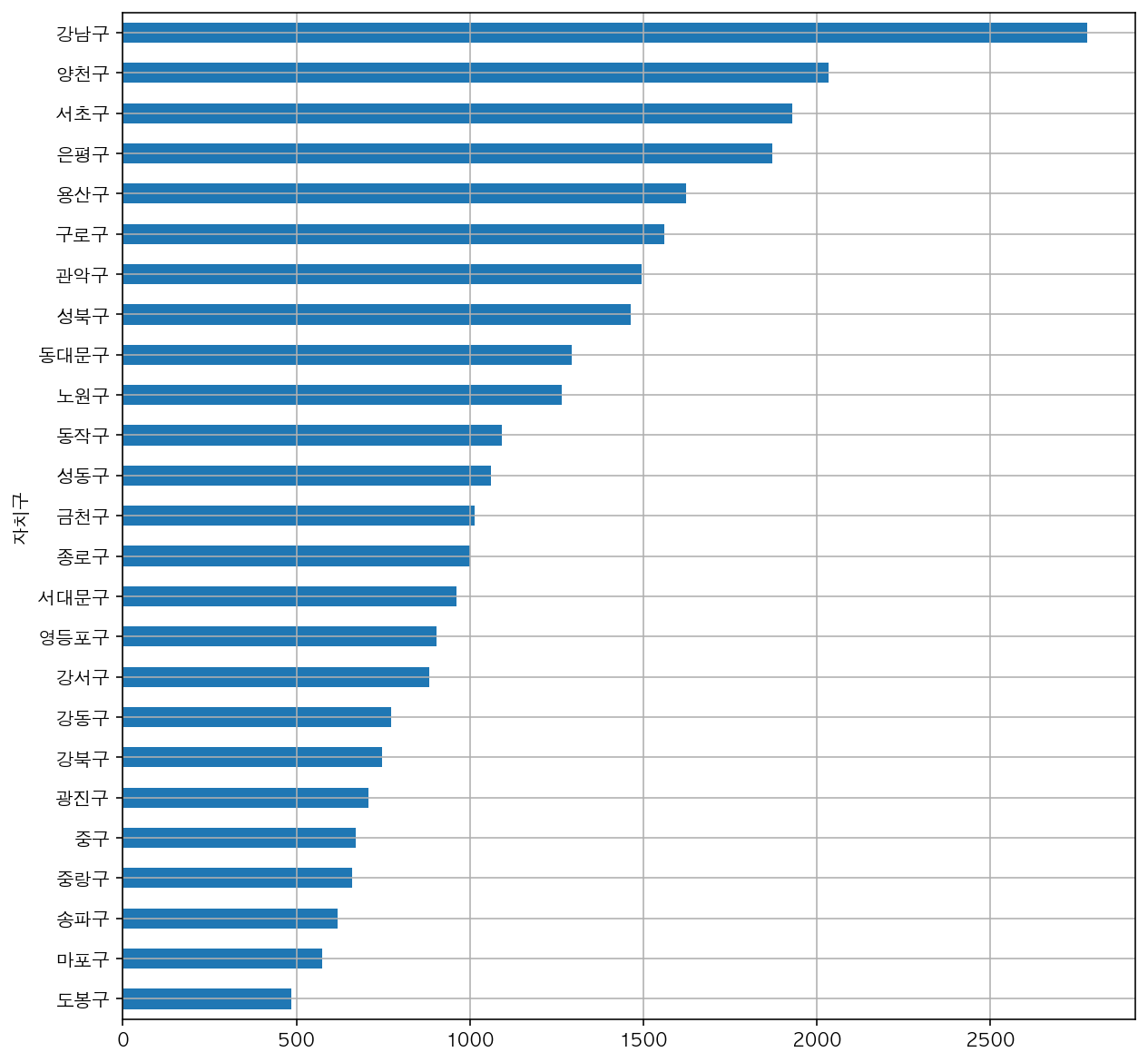
3) 인구수 대비 CCTV비율 시각화
data_result['CCTV비율'] = data_result['소계'] / data_result['인구수'] * 100
data_result['CCTV비율'].sort_values().plot(kind='barh',
grid=True,
figsize=(10, 10))
plt.show()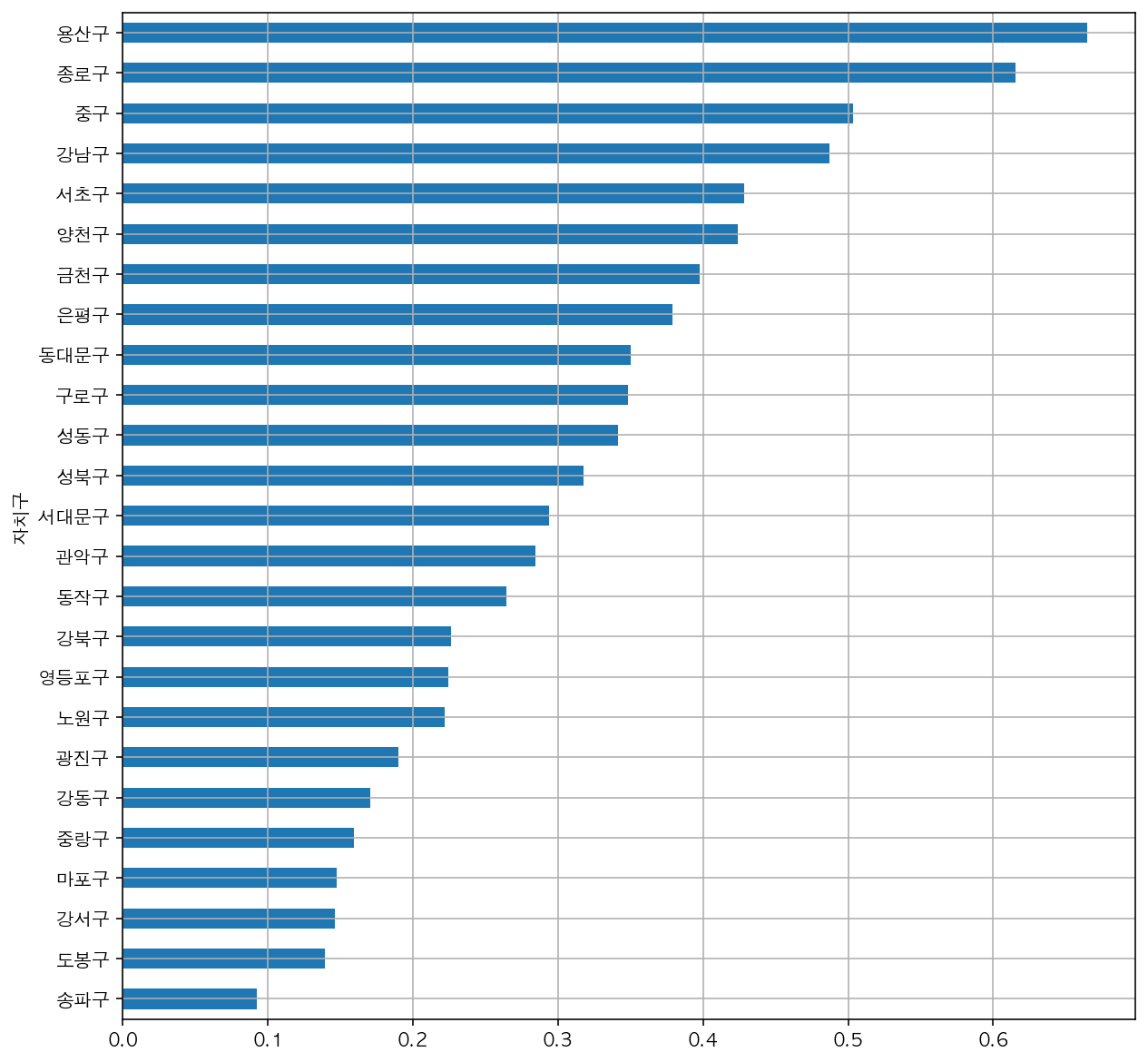
4) 인구수와 소계에 대한 산점도
plt.figure(figsize=(6, 6))
plt.scatter(data_result['인구수'], data_result['소계'], s=50) #s:산점도 점 크기
plt.xlabel('인구수')
plt.ylabel('cctv')
plt.grid()
plt.show()
5) 인구수와 CCTV비율에 대한 산점도
plt.figure(figsize=(6, 6))
plt.scatter(data_result['인구수'], data_result['CCTV비율'], s=50)
plt.xlabel('인구수')
plt.ylabel('cctv')
plt.grid()
plt.show()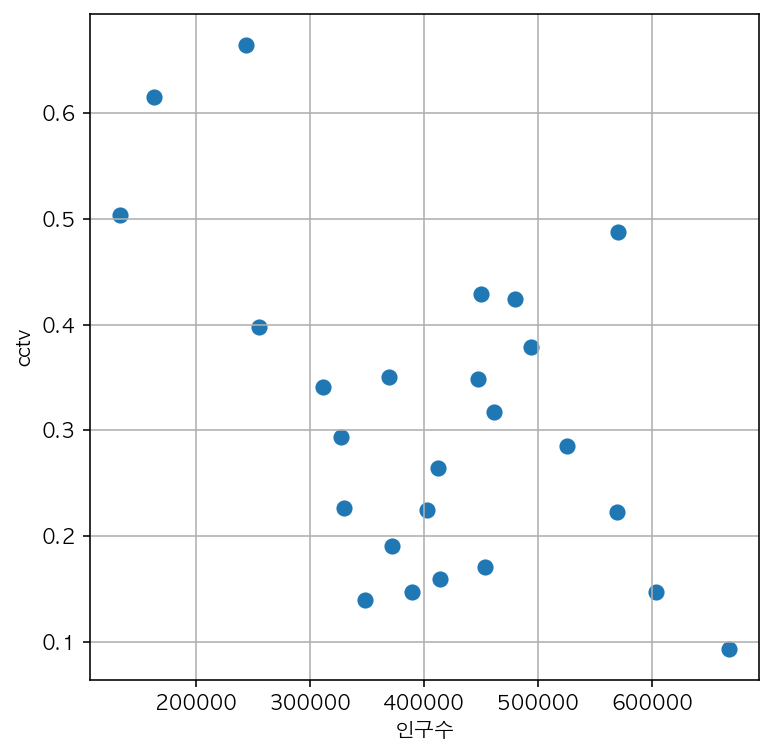
6) 인구수와 CCTV비율에 대한 산점도의 선형회귀선 *선형회귀 : 두 변수(열)의 관계
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1) #직선 만들기
fx = np.linspace(100000, 700000, 100) #(부터, 까지, 간격)으로 그리기
plt.figure(figsize=(10,10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='r') #ls : line style, lw : line width
plt.xlabel('인구수')
plt.ylabel('cctv')
plt.grid()
plt.show()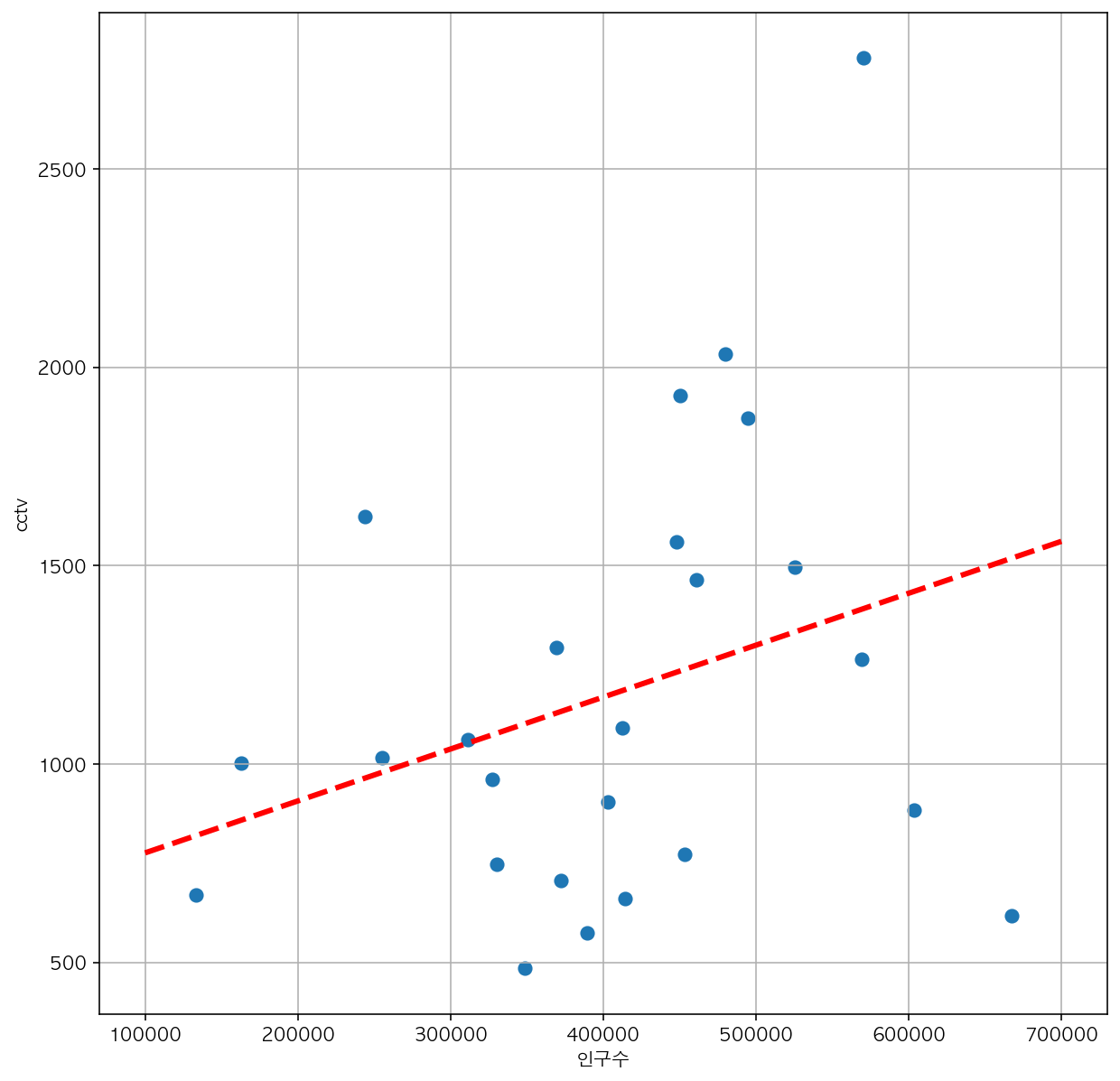
6. 결론
서울시 내 강남구, 양천구, 용산구, 서초구, 은평구는 인구 대비 cctv가 많고,
강서구, 송파구, 도봉구 등은 인구 대비 부족함. 따라서 강남 3구 전체가 안전하다고 판단하기는 어려움.
7. 시각화 심화하기
7-1. '오차' 산출 : data_result['소계'] - data_result['인구수']
절댓값 산출 : Numpy.abs()
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)
data_result['오차'] = np.abs(data_result['소계'] - f1(data_result['인구수']))
df_sort = data_result.sort_values(by='오차', ascending=False)7-2. 시각화
plt.figure(figsize=(14, 10))
plt.scatter(df_sort['인구수'], df_sort['소계'],
c=data_result['오차'],
s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='r')
for n in range(10):
plt.text(df_sort['인구수'][n]*1.02, #x좌표
df_sort['소계'][n]*0.98, #y좌표
df_sort.index[n], #자치구
fontsize=15)
plt.xlabel('인구수')
plt.ylabel('인구당 비율')
plt.colorbar()
plt.grid()
plt.show()