LG U+ why not SW 5/python DA _ exercise
파이썬 데이터 분석 예제 _ 우리 동네 인구 데이터 연령 및 성별 간단 분석 / 파이차트, 산점도, 추세선
wangatheringdata
2025. 3. 9. 19:43
파이썬
1. 모듈 import 및 데이터 추출, 시각화
import csv
import matplotlib.pyplot as plt
f = open('./data/gender.csv', 'r', encoding='cp949')
data = csv.reader(f)
m = [] #3:104 _ csv 상 데이터의 분포
f = [] #106: _ csv 상 데이터의 분포
name = input('찾을 지역을 입력하세요! _ ').strip()
for row in data :
if '신도림' in row[0] :
for i in row[3:104] :
#0기준으로 봤을 때 m의 자료가 왼쪽으로 위치한다고 하면, 모든 자료는 -int
m.append(-int(i))
for i in row[106:] :
f.append(int(i))
print(len(m), len(f)) #808 808
plt.style.use('ggplot')
plt.figure(figsize=(10, 5), dpi=300)
plt.rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus']=False #-값 부분이 손상됨을 방지
plt.title('지역의 남녀 성별 인구 분포')
plt.barh(range(808), m, label='남자') #range는 위 len() 값과 일치해야 실행됨
plt.barh(range(808), f, label='여자')
plt.legend()
plt.title(name + ' 지역의 남녀 성별 인구 분포')
plt.show()
2. 파이차트를 이용한 시각화
2-1. 파이차트 : .pie()
전체 데이터 중 특정 데이터의 비율을 파이 형태로 표현
plt.pie([10, 20])
plt.show()
size = [2441, 2312, 1031, 1233]
label = ['A형', 'B형', 'AB형', '0형']
color = ['r', 'g', 'b', 'y']
plt.axis('equal')
plt.rc('font', family='AppleGothic')
plt.pie(size,
labels=label,
autopct='%.1f%%', #'%.1f%%' : 소숫점 이하 1자리
colors=color,
explode=(0, 0.1, 0, 0)) #explode=() : 조각 띄우기
plt.legend()
plt.show()2-2. 파이차트로 성별 분포 시각화
f = open('./data/gender.csv', 'r', encoding='cp949')
data = csv.reader(f)
name = input('찾을 지역을 입력하세요!_')
size = [] #남자 /여자
for row in data:
if name in row[0]:
m = 0
f = 0
for i in range(101):
m += int(row[i+3])
f += int(row[i+106])
break #101개까지만 누적시키기 위함
size.append(m)
size.append(f)
color = ['r', 'g']
label = ['남', '여']
plt.axis('equal')
plt.rc('font', family='AppleGothic')
plt.pie(size,
labels=label,
autopct='%.1f%%',
colors=color,
startangle=90) #startangle=90은 12시방향부터 시작
plt.legend()
plt.title(name + ' 지역의 남녀 성별 인구 분포')
plt.show()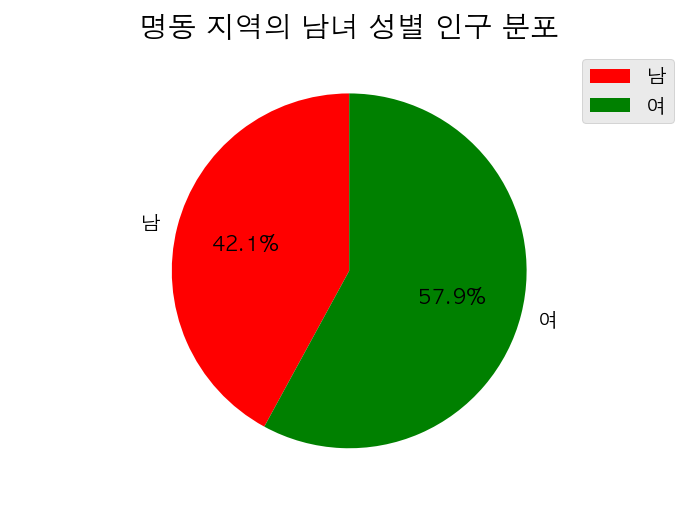
3. 산점도 : .scatter()
점이 흩어진 모양의 그래프로 x축과 y축 데이터의 상관 관계 표현하고, 두개의 축 기준으로 데이터의 분포, 산포도 표현
x = [1, 2, 3, 4]
y = [10, 20, 30, 40]
color = ['r', 'g', 'b', 'y'] #list 갯수와 일치
plt.style.use('ggplot')
plt.scatter(x, y)
plt.show()
x = [1, 2, 3, 4]
y = [10, 20, 30, 40]
size = [100, 25, 200, 180] #list 갯수와 일치
plt.style.use('ggplot')
plt.scatter(x, y, s=size, c=range(4), cmap='jet')
plt.colorbar()
plt.show()
3-1. 산점도로 특정 지역의 인구 분포 시각화
f = open('./data/gender.csv', 'r', encoding='cp949')
data = csv.reader(f)
m = []
f = []
name = input('찾을 지역(도)을 입력하세요!_').strip
for row in data :
if name in row[0] :
for i in range(3, 104) :
m.append(int(row[i]))
f.append(int(row[i+103]))
break
plt.style.use('ggplot')
plt.scatter(m, f, c=range(101), cmap='jet', alpha=0.5) #alpha: 투명도
plt.colorbar()
plt.title(name + ' 지역 성별 인구 분포')
plt.show()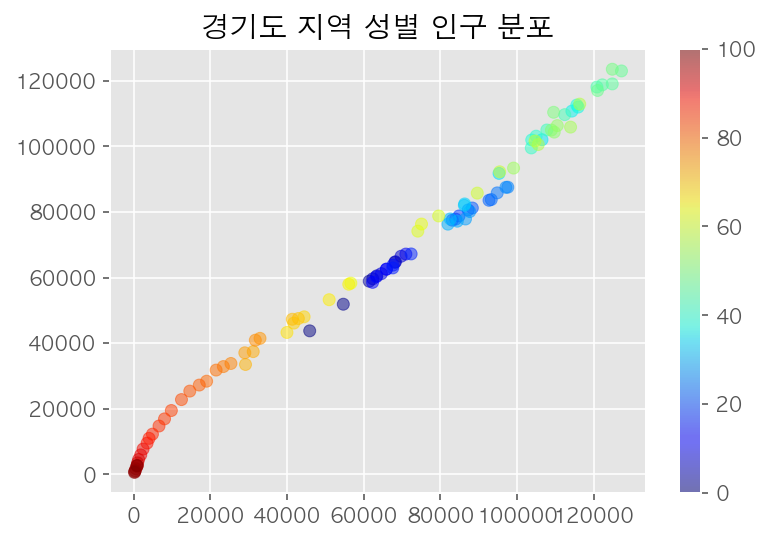
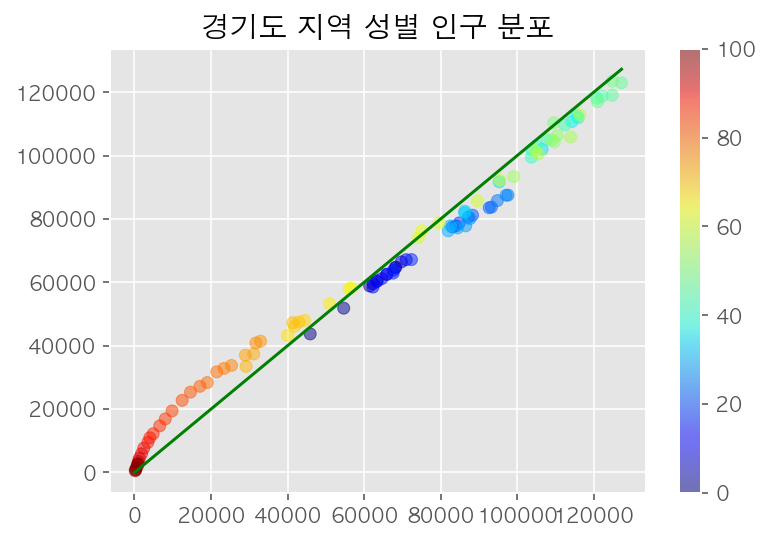
3-2. 추세선 : .plot()
남성 인구 수 중 가장 큰 값을 기준으로 y = x형태의 직선 삽입
f = open('./data/gender.csv', 'r', encoding='cp949')
data = csv.reader(f)
m = []
f = []
name = input('찾을 지역(도)을 입력하세요!_').strip
for row in data :
if name in row[0] :
for i in range(3, 104) :
m.append(int(row[i]))
f.append(int(row[i+103]))
break
plt.style.use('ggplot')
plt.rc('font', family='AppleGothic')
plt.scatter(m, f, c=range(101), cmap='jet', alpha=0.5)
plt.colorbar()
#추세선
plt.plot(range(max(m)), range(max(m)), 'g')
plt.title(name + ' 지역 성별 인구 분포')
plt.show()