파이썬
1. 개요
주제 : 한국인 삶의 질 파악
데이터 분석 절차
1. 변수(열) 검토 및 전처리 :
변수의 특징 파악 : 이상치, 결측치 정제 - 분석의 용이성(변수의 값 처리)
전처리 - 분석할 변수 각각 진행
2. 변수 간 관계 분석 :
2-1 요약 테이블
2-2 시각화
2. 모듈 import 및 파일 읽기
1-1. 모듈 import
sav파일 읽기 : 아나콘다 프롬프트에 pip install pyreadstat 설치 필수
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns2-1. 파일 읽기 및 복사본 저장
raw_welfare = pd.read_spss('./data/Koweps_hpwc14_2019_beta2.sav')
welfare = raw_welfare.copy()
3. 데이터 검토
3-1. 데이터 검토
#앞/뒷부분 확인
welfare.head()
welfare.tail()
#행, 열 확인
welfare.shape
#변수 속성 확인
welfare.info()
#요약 통계량 확인
welfare.describe()
'''
h14_id h14_ind ... h14_pers_income4 h14_pers_income5
count 14418.000000 14418.000000 ... 14418.000000 715.000000
mean 4672.108406 3.121723 ... 2.038702 1183.292308
std 2792.998128 3.297963 ... 32.965477 2147.418274
min 2.000000 1.000000 ... 0.000000 -10600.000000
25% 2356.000000 1.000000 ... 0.000000 206.000000
50% 4535.000000 1.000000 ... 0.000000 530.000000
75% 6616.000000 7.000000 ... 0.000000 1295.000000
max 9800.000000 14.000000 ... 3000.000000 22644.000000
[8 rows x 826 columns]
'''3-2. 변수 이름 변경
#성별, 출생년도, 혼인상태, 종교, 수입, 직업코드, 지역코드
welfare = welfare.rename(columns = {'h14_g3' : 'gender',
'h14_g4' : 'birth',
'h14_g10' : 'marriage_type',
'h14_g11' : 'religion',
'p1402_8aq1' : 'income',
'h14_eco9' : 'code_job',
'h14_reg7' : 'code_region'})4. 분석 및 시각화
4-1. 성별에 따른 월급 차이
1) 성별 변수 검토 및 전처리
#1. 변수 검토 : 타입 파악, 범주 당 인원수
welfare['gender'].dtypes
#2. 빈도 및 이상치 구하기
welfare['gender'].value_counts()
#만일 이상치가 발견됐을 경우, 이상치 결측 처리
welfare['gender'] = np.where(welfare['gender'] == 9, np.nan, welfare['gender'])
#결측치 확인
welfare['gender'].isna().sum()
#결측치 제거 : .dropna()
#성별 항목 이름 부여
welfare['gender'] = np.where(welfare['gender'] == 1, 'male', 'female')
welfare['gender'].value_counts()
2) 시각화
sns.countplot(data = welfare, x = 'gender')
plt.show()
3) 수입 변수 검토 및 전처리
welfare['income'].dtypes
welfare['income'].describe()
sns.histplot(data = welfare, x = 'income')
plt.show()
#히스토그램이 한쪽으로 치우침
#이상치 확인
welfare['income'].describe()
#결측치 확인
welfare['income'].isna().sum()
4) 성별 수입 차이 분석 및 시각화
성별 수입 평균표 : gender_income
income 결측치 제거 : welfare.dropna(subset = 'income')
gender별 분리 : groupby('gender', as_index = False)
income 평균 산출 : agg(mean_income = ('income', 'mean'))
gender_income = welfare.dropna(subset = 'income').groupby('gender', as_index = False).agg(mean_income = ('income', 'mean'))
#시각화
sns.barplot(data = gender_income, x = 'gender', y = 'mean_income')
plt.show()
4-2. 연령별 수입 차이
1) 파생 변수 'age' 선언 : .assign()
#2019자료이므로 2019만큼 뺀 후 1씩 더하기
welfare = welfare.assign(age = 2019 - welfare['birth'] + 1)
welfare['age'].describe()
sns.histplot(data = welfare, x = 'age')
plt.show()
2) 연령별 수입 차이 분석 및 시각화
나이별 수입 평균표 : age_income
income 결측치 제거 : welfare.dropna(subset = 'income')
age별 분리 : groupby('age')
income 평균 구하기 : agg(mean_income = ('income', 'mean'))
age_income = welfare.dropna(subset = 'income').groupby('age').agg(mean_income = ('income', 'mean'))
#시각화
sns.lineplot(data = age_income, x = 'age', y = 'mean_income')
plt.show()
4-3. 연령대별 수입 차이
1) 연령대 변수 선언 : 초년(30세미만) / 중년 / 노년(59세이상) _ .assign() / numpy.where()
np.where(welfare['age'] < 30, 'young', np.where(welfare['age'] <= 59, 'middle', 'old'))
=> if / elif / else 구조와 같음
welfare['age'].head()
#연령대 변수 선언
welfare = welfare.assign(ageg = np.where(welfare['age'] < 30, 'young', np.where(welfare['age'] <= 59, 'middle', 'old')))
#빈도 산출
welfare['ageg'].value_counts()
#시각화
sns.countplot(data = welfare, x = 'ageg')
plt.show()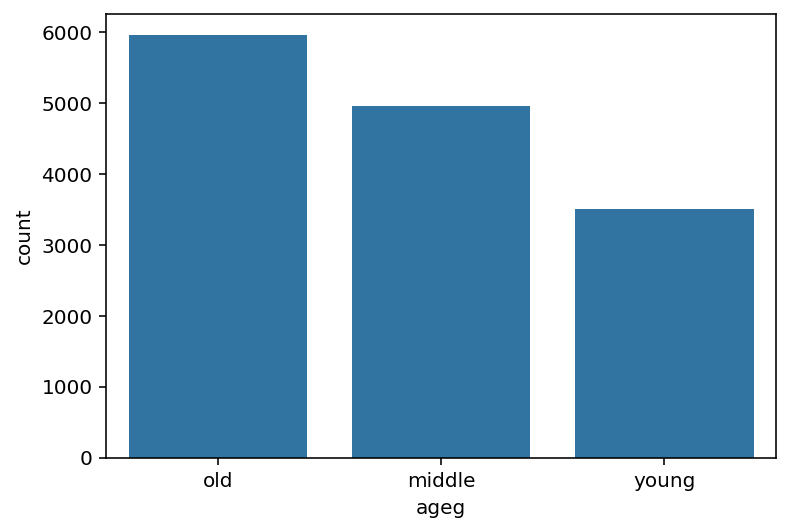
2) 결측치 제거 후 수입 평균 산출
연령대별 수입 평균표 : ageg_income
income 결측치 제거 : .dropna(subset = 'income')
ageg별로 분리 : .groupby(['ageg'], as_index = False)
income 평균 구하기 : .agg(mean_income = ('income', 'mean'))
ageg_income = welfare.dropna(subset = 'income').groupby(['ageg'], as_index = False).agg(mean_income = ('income', 'mean'))
#시각화 1
sns.barplot(data = ageg_income, x = 'ageg', y = 'mean_income')
plt.show()
#시각화 2
sns.barplot(data = ageg_income, x = 'ageg', y = 'mean_income', order = ['young', 'middle', 'old'])
plt.show()

4-4. 연령대 및 성별 수입 차이
1) 연령대 및 성별 평균표
성별 항목이 male / female 두개 이므로 hue='gender'
gender_income = welfare.dropna(subset = 'income').groupby(['ageg', 'gender'], as_index = False).agg(mean_income = ('income', 'mean'))
#시각화
sns.barplot(data = gender_income, x = 'ageg', y = 'mean_income', hue = 'gender', order = ['young', 'middle', 'old'])
plt.show()
2) 연령 및 성별 수입 차이
gender_age = welfare.dropna(subset = 'income').groupby(['age', 'gender'], as_index = False).agg(mean_income = ('income', 'mean'))
gender_age.head()
'''
age gender mean_income
0 19.0 male 162.000000
1 20.0 female 87.666667
2 20.0 male 155.000000
3 21.0 female 124.000000
4 21.0 male 186.000000
'''
#추세선
sns.lineplot(data = gender_age, x = 'age', y = 'mean_income', hue = 'gender')
plt.show()
3) 결론
남자는 50세 기준으로 증가치가 급격히 감소, 여자는 30대중반 기준으로 완만하게 감소한다.
성별 수입 차이는 30대 이후로 급격히 벌어짐
4-5. 직업별 수입 차이
1) 인구 데이터와 직종 분류 데이터 병합
welfare['code_job'].dtypes
welfare['code_job'].value_counts()
#직종 코드 데이터 읽기
list_job = pd.read_excel('./data/Koweps_Codebook_2019.xlsx', sheet_name = '직종코드')
list_job.head()
list_job.shape
#welfare 데이터에 list_job 데이터 결합
welfare = welfare.merge(list_job, how = 'left', on = 'code_job') #how=어느쪽으로, on=공통키
#code_job 결측치 제거 후, code_job, job 출력
welfare.dropna(subset = 'code_job')[['code_job', 'job']].head()
2) 직업별 수입 평균표
job_income = welfare.dropna(subset = ['job', 'income']).groupby('job', as_index = False).agg(mean_income = ('income', 'mean'))
import matplotlib.pyplot as plt
plt.rcParams.update({'font.family' : 'AppleGothic'})
#수입이 많은 직업 상위 10개 시각화
top10 = job_income.sort_values('mean_income', ascending = False).head(10)
sns.barplot(data = top10, y = 'job', x = 'mean_income')
plt.show()
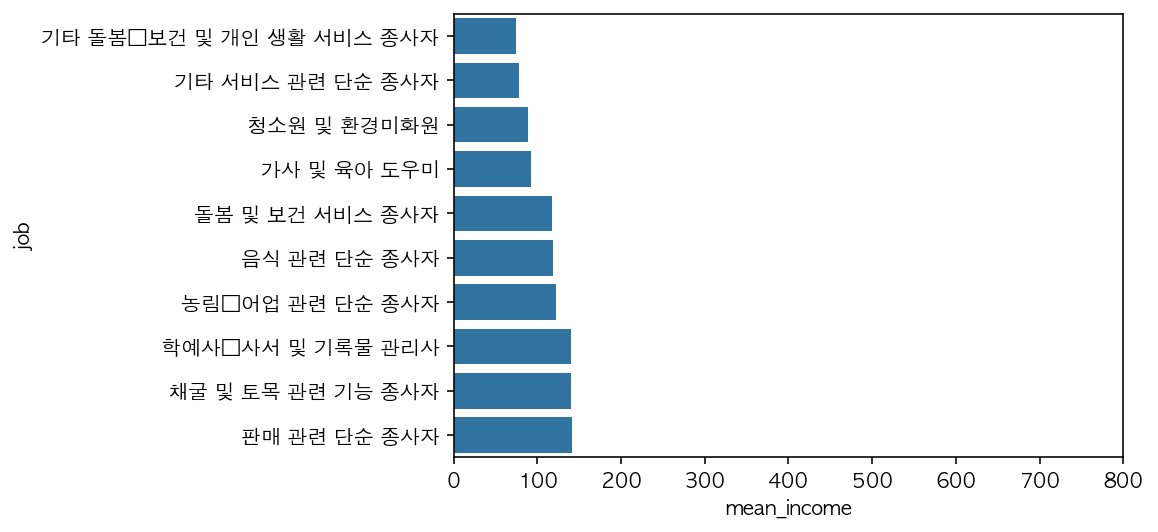
#수입이 적은 직업 하위 10개 시각화
bottom10 = job_income.sort_values('mean_income').head(10)
sns.barplot(data = bottom10, y = 'job', x = 'mean_income').set(xlim = [0, 800])
plt.show()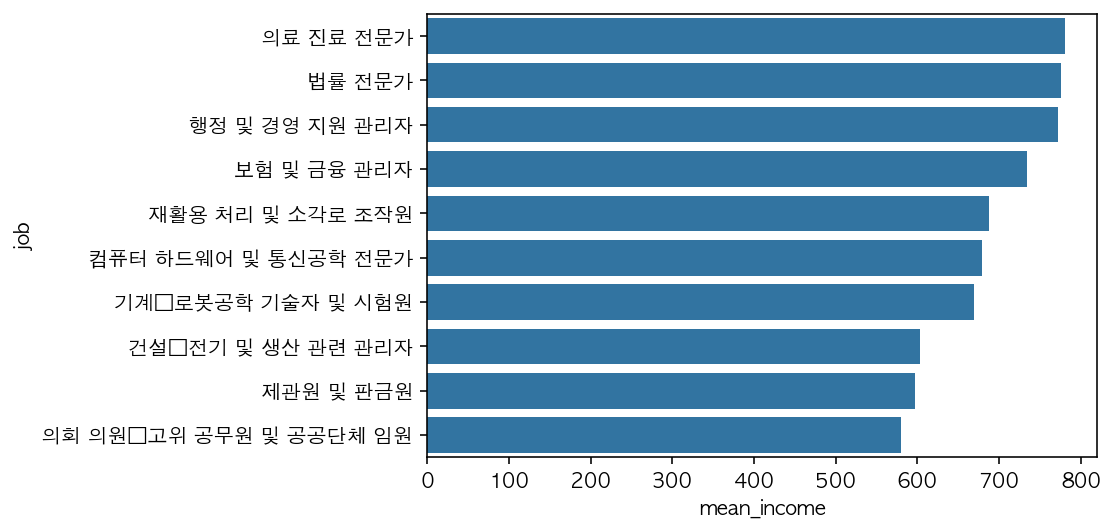
4-6. 성별 직업 빈도
1) 남성 직업 빈도 상위 10개 추출
#job 결측치 제거
#male 추출 : .query("컬럼이름 == 'male'")
#job별 분리
#job빈도 구하기
#내림차순 정렬
#상위 10행 추출
job_male = welfare.dropna(subset = 'job').query("gender == 'male'").groupby('job', as_index = False).agg(n = ('job', 'count')).sort_values('n', ascending = False).head(10)
#시각화
sns.barplot(data = job_male, y = 'job', x = 'n').set(xlim = [0, 500])
plt.show()
2) 여성 직업 빈도 상위 10개 추출
#job 결측치 제거
#female 추출 : .query("컬럼이름 == 'female'")
#job별 분리
#job빈도 구하기
#내림차순 정렬
#상위 10행 추출
job_female = welfare.dropna(subset = 'job').query("gender == 'female'").groupby('job', as_index = False).agg(n = ('job', 'count')).sort_values('n', ascending = False).head(10)
#시각화
sns.barplot(data = job_female, y = 'job', x = 'n').set(xlim = [0, 500])
plt.show()
3) 결과
공통 : 작물재배종사자
남성 : 자동차운전원 - 경영관련사무원 - 매장판매종사자 순서
여성 : 청소원및환경미화원 - 매장판매종사자 - 회계및경리사무원 순서
4-7. 지역별 연령대 비율
출생년도를 나이로 환산
65세 이상만 데이터로 사용
65세 이상 연령 데이터를 지역별로 연령 분류
지역별 전체 인구수 대비 노년층 비율
welfare = welfare.assign(code_region = np.where(welfare['code_region'] == 1, '서울',
np.where(welfare['code_region'] == 2, '수도권(인천/경기)',
np.where(welfare['code_region'] == 3, '부산/경남/울산',
np.where(welfare['code_region'] == 4, '대구/경북',
np.where(welfare['code_region'] == 5, '대전/충남',
np.where(welfare['code_region'] == 6, '충북/강원', '광주/전남/전북/제주도')))))))
welfare['code_region'].dtypes
welfare['code_region'].value_counts()
welfare['code_region'].shape
welfare.dropna(subset = 'code_region')[['code_region', 'birth']].head()
welfare = welfare.assign(age = 2019 - welfare['birth'] + 1)
welfare['age'].describe()
welfare = welfare.assign(ob = welfare['age'] >= 65)
welfare['ob'].dtypes
welfare['ob'].value_counts()
welfare['ob'].shape
age_ob = welfare.dropna(subset = 'ob').groupby('code_region', as_index = False).agg(mean_ob = ('ob', 'mean'))
top_ob = age_ob.sort_values('mean_ob', ascending = False).head(7)
welfare = welfare.assign(yb = welfare['age'] <= 65)
welfare['yb'].dtypes
welfare['yb'].value_counts()
welfare['yb'].shape
age_yb = welfare.dropna(subset = 'yb').groupby('code_region', as_index = False).agg(mean_yb = ('yb', 'sum'))
pop = age_yb.sort_values('mean_yb', ascending = False).head(7)4-8. 종교 유무에 따른 이혼율
1) 종교 데이터 확인
#종교 부분 확인
welfare['religion'].dtypes
#이상치 유무 확인, 두가지 답변이므로 01/02 두 항목만 있어야 함
welfare['religion'].value_counts()
#결측 확인
welfare['religion'].isna().sum()
#01/02를 있다/없다 직관적으로 변경
welfare['religion'] = np.where(welfare['religion'] == 1, 'o', 'x')
#변경 확인
welfare['religion'].value_counts()
2) 혼인 데이터 확인
#혼인 부분 확인
welfare['marriage_type'].dtypes
#이상치 유무 확인, 여섯가지 답변이므로 01~06 항목만 있어야 함
welfare['marriage_type'].value_counts()
'''
marriage_type
1.0 7190 결혼
5.0 2357
0.0 2121
2.0 1954
3.0 689 이혼
4.0 78
6.0 29
'''
welfare['marriage_type'].isna().sum()
#이혼 여부를 확인하는 변수 생성
welfare['marriage'] = np.where(welfare['marriage_type'] == 1, 'marriage', np.where(welfare['marriage_type'] == 3, 'divorced', 'etc'))
'''
welfare['marriage']라는 변수를 생성하는데,
np.where(welfare['marriage_type'] == 1, 이라면 'marriage', 를 넣고,
아니라면 np.where(welfare['marriage_type'] == 3, 이라면 'divorced', 를 넣고,
아니라면 'etc'))를 넣고 끝낸다.
'''
3) 이혼 여부별 빈도 산출
welfare['marriage'].head()
#새로운 변수 선언해 marriage별 분리
n_divo = welfare.groupby('marriage', as_index = False).agg(n = ('marriage', 'count'))
'''
n = (merriage열을 count한 결과값을 담는)열
'''
#marriage별 빈도 구하기
n_divo.value_counts()
4) 종교 유무에 따른 이혼율 분석하기
etc는 제외한 종교 유무에 따른 이혼율 산출
#religion별 분리해 marriage 추출 후, 비율 구하기
rel_divo = welfare.query('marriage != "etc"').groupby('religion', as_index = False)['marriage'].value_counts(normalize=True)
'''
.query() : 조건을 넣어 데이터를 필터링
.value_counts(normalize=True)로 비율을 구할 수 있음
rel_divo 라는 변수를 생성하는데,
welfare.query('marriage != "etc"')
: welfare의 marriage열이 "etc"값을 갖지 않은 항목만 필터링해
.groupby('religion', as_index = False)['marriage']
: marriage열을 religion열 기준으로 그룹화 할 것 index는 고려하지 않고
.value_counts(normalize=True)
: rel_divo 값을 비율을 산출한다.
'''
#위 결과 divorced추출 후, 소숫점은 반올림해 백분율로 바꾸기
rel_divo = rel_divo.query('marriage == "divorced"').assign(proportion = rel_divo['proportion'] * 100).round(1)
'''
.round(1) : 소숫점 한자리까지만 남김
rel_divo는 rel_divo인데
.query('marriage == "divorced"')
: marriage열이 "divorced"값을 가진 항목만 필터링해
.assign(proportion = rel_divo['proportion'] * 100)
: proportion열을 새로 만들 건데 그 값은 rel_divo의 proportion열의 값에 100을 곱하고
.round(1)
: 소숫점 한자리까지만 남긴 값이다.
'''
5) 결론
비교 결과 수치 상 유의미한 연관성은 발견되지 않음
4-9. 연령대별 종교 유무에 따른 이혼율
1) etc를 제외한 연령별 이혼율 변수 생성
#ageg별로 분리해 marriage 추출 후, 비율 구하기
age_div = welfare.query('ageg != "young" | marriage == "divored"').groupby('ageg', as_index = False)['marriage'].value_counts(normalize=True)
#초년층 제외한 이혼 추출 후, 백분율로 변경 후 반올림
age_div = age_div.query('marriage == "divorced"').assign(proportion = age_div['proportion'] * 100).round(1)
#etc와 초년층을 제외한 연령대별 종교 유무에 따른 이혼율을 marriage열로 추출 후, 비율 구하기
age_rel_div = welfare.query('marriage != "etc" | ageg != "young"').groupby(['ageg', 'religion'], as_index = False)['marriage'].value_counts(normalize=True)
#divorced 추출 후 백분율로 바꾸고 반올림
age_rel_div = rel_divo.query('marriage == "divorced"').assign(proportion = age_rel_div['proportion'] * 100).round(1)
2) 결론
유의미하게 종교가 있는 사람 중 이혼율이 더 낮게 집계됨
4-9-1. 지역별 연령대 비율
1) 지역 변수 검토 및 전처리
지역명을 코드값에서 이름으로 변수 추가
지역별 연령대 비율로 비율표 생성
welfare['code_region'].dtypes
#이상치 유무 확인
welfare['code_region'].value_counts()
welfare['code_region'].isna().sum()
#코드값인 지역명을 codebook상의 지역명으로 변경
list_region = pd.DataFrame({'code_region' : [1, 2, 3, 4, 5, 6, 7],
'region' : ['서울', '수도권', '경남', '경북', '충남', '충북/강원', '전라/제주도']})
#지역변수명 추가
welfare = welfare.merge(list_region, how = 'left', on = 'code_region')
welfare['region']
#지역별 연령대 비율로 비율표 생성
#region별 분리하여 ageg 추출
#비율 구하기
region_ageg = welfare.groupby('region', as_index=False)['ageg'].value_counts(normalize=True)
#백분율로
region_ageg = region_ageg.assign(proportion = region_ageg['proportion'] * 100).round(1)
plt.rcParams['font.family'] = 'AppleGothic' # 맥북 기본 한글 폰트
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호 깨짐 방지
sns.barplot(data = region_ageg, y = 'region', x = 'proportion', hue = 'ageg')
plt.show()
2) pivot 생성
표의 행렬을 뒤바꿔 구성 변경
누적그래프로 시각화 시 사용
2-1) 지역, 연령대, 비율을 추출
region_ageg[['region', 'ageg', 'proportion']]
2-2) DataFrame.pivot()
2-1. 지역을 기준으로 : index=지역
2-2. 연령대별로 컬럼 구성 : columns = 연령대
2-3. 각 항목의 값을 비율로 채우기 : values = 비율
pivot_df = region_ageg[['region', 'ageg', 'proportion']].pivot(index = 'region', columns = 'ageg', values = 'proportion')
pivot_df.plot.barh(stacked = True) #.barh(stacked = True) barh형태로 쌓아라stacked
plt.show()
#노년이 보기 쉽게 컬럼 위치 변경하기
reorder_df = pivot_df.sort_values('old')[['young', 'middle', 'old']]
reorder_df.plot.barh(stacked = True)
plt.show()
'LG U+ why not SW 5 > python DA _ exercise' 카테고리의 다른 글
| 파이썬 데이터 분석 예제 _ 우리 동네 인구 데이터 연령 및 성별 간단 분석 / 파이차트, 산점도, 추세선 (0) | 2025.03.09 |
|---|---|
| 파이썬 데이터 분석 예제 _ 우리 동네 인구 데이터 간단 분석 (0) | 2025.03.09 |
| 파이썬 데이터 분석 예제 _ 서울시 날씨 데이터 간단 분석 및 시각화 / 히스토그램, 박스플롯 (1) | 2025.03.05 |
| 파이썬 데이터 분석 예제 _ 서울시 각 자치구 cctv와 인구 데이터 분석 (0) | 2025.03.03 |
| 파이썬 데이터 분석 예제 _ 간단한 날씨 데이터 분석 (0) | 2025.03.03 |